所谓boosting方法就是结合多个弱分类器,形成一个强分类器的方法。adaboost是其中一种,全名adaptive boosting。其目的是学习各个弱分类器的权重$\alpha_m$ \begin{equation}Y_M(x)=sign(\sum_{m=1}^M\alpha_my_m(x)) \end{equation} 其中$y_m()$是第m个弱分类器,$Y_M()$是最后学习到的分类器。直观上我们可以这样考虑,对于好的弱分类器,权重就大,不好的分类器,权重就小。如果用$\epsilon$表示错误率的话,可以想象$\alpha_m$应该是和$\epsilon_m$是一个反比的关系。那么上一个分类器结果如何影响下一个分类器的权重呢,这就是策略问题。adaboot采用的是把每一个样本赋一个权值,最优化分错样本的权值比,如果本次分类把某个点分错了,就把分错点的权值增大。
来看下PRML里的步骤,了无秘密:

再看一张整个过程图
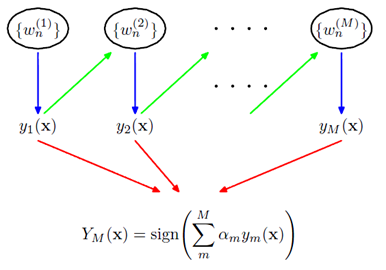
可以看出来adaboost只是能学习出弱分类器的权值,不能作用于弱分类器本身,并且只是线性的连接弱分类器。可以想象下它的局限性。那么除了给每个样本分配一个权值的策略外,还有更好的策略吗?由于样本的权值由上一个$\alpha_m$影响,那么弱分类器的顺序对结果有影响吗?非线性的结合是否比线性的结果好呢?