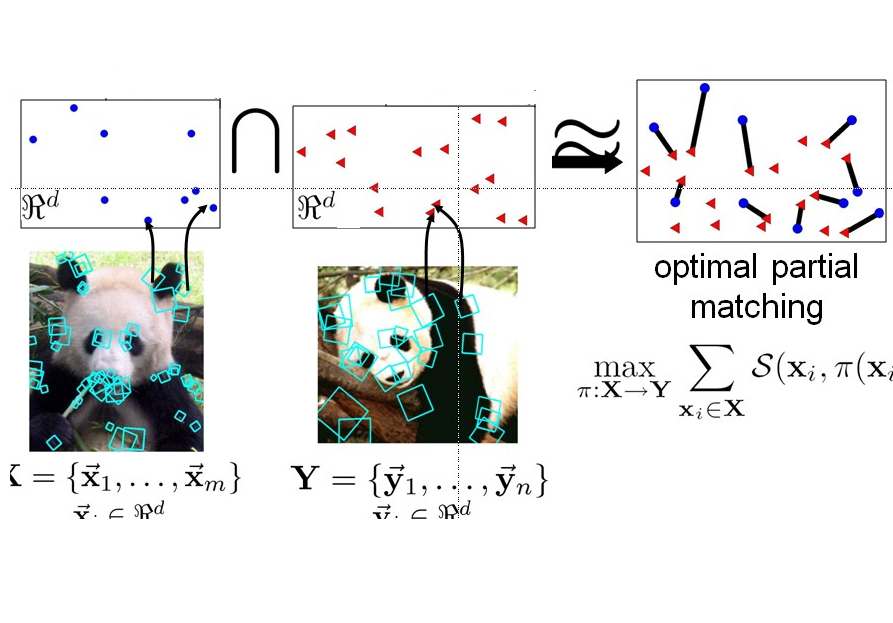
 所谓的match,其实match的是两个图片描述符,计算其similarity,以此进行classification或recognizing。普通的BOF方法就是:首先用sift描述符描绘图像的interest of region,然后进行聚类,得到具有索引的dictionary,从而建立起直方图的描述符便具有了识别一个物体的功能。
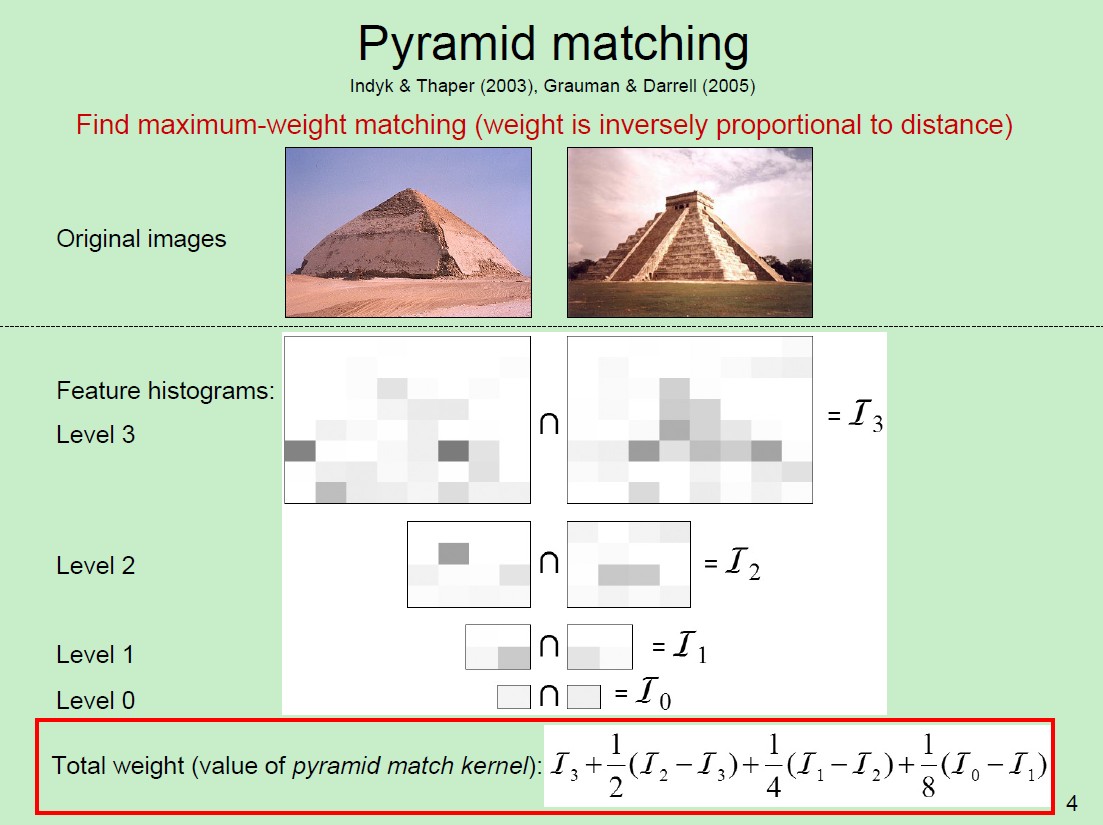
所谓的match,其实match的是两个图片描述符,计算其similarity,以此进行classification或recognizing。普通的BOF方法就是:首先用sift描述符描绘图像的interest of region,然后进行聚类,得到具有索引的dictionary,从而建立起直方图的描述符便具有了识别一个物体的功能。我们做 object recognizing时,bag of features(BOF)方法的效率给人留下深刻的印象。然而常用SVM的核函数往往用于固定长度的输入,并不适合这种无序的,长度不同的BOF的描述符输入。Kristen Grauman于2005年提出SPM核函数,这种把方法把feature投射到不同尺度的金字塔直方图上,然后计算出加权的histogram intersection。这种方法得到的结果很好,之后人们又对它进行了进一步的改进。
本文并不尝试将英文的论文翻译于此,其中的细节见文末的附的两篇论文。这里我贴一些图片,并简要谈谈我的理解。
所谓的match,其实match的是两个图片描述符,计算其similarity,以此进行classification或recognizing。普通的BOF方法就是:首先用sift描述符描绘图像的interest of region,然后进行聚类,得到具有索引的dictionary,从而建立起直方图的描述符便具有了识别一个物体的功能。
那么spm方法的优势在哪里呢?观察上图你会发现,普通的BOF方法在计算similarity时只是在一个尺度上计算的,而spm是将一个描述符映射到不同的尺度空间,然后计算上个尺度和本尺度的相关的差值,最后求的是把这些差值加权的值,无疑直观上讲,后者的准确性会比普通的BOF好,同时实验也证明了同样的结论。
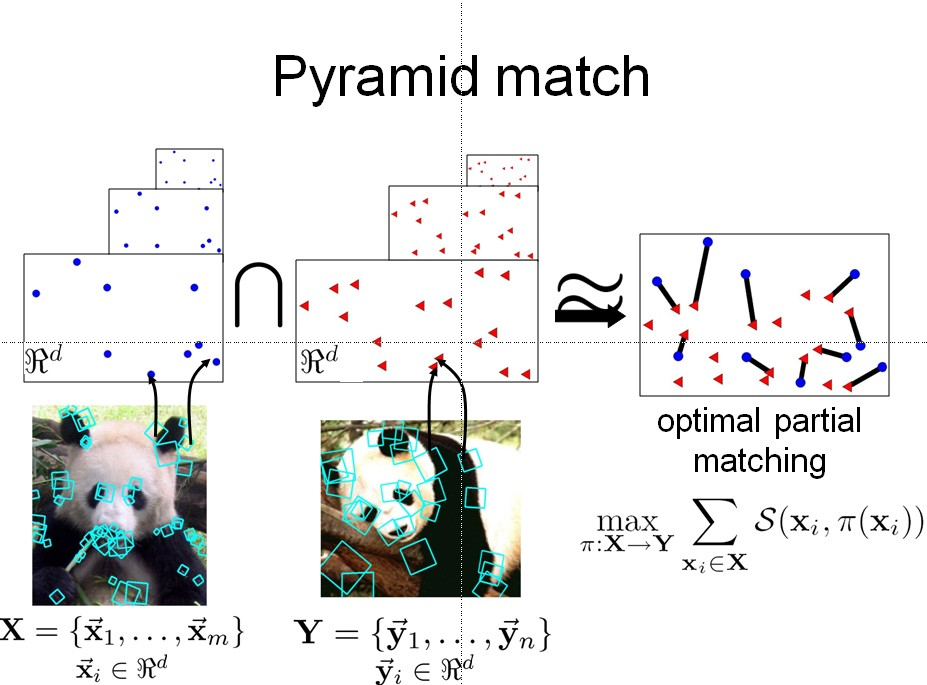
如果你理解了Grauman 的方法后,那么Lazebnik的方法也应该比较容易理解。其实Lazebnik方法是在Grauman 的方法上进行了一点改进。她在描述符映射到不同尺度空间之后,同时也在不同尺度上将图片划分成不同的小块,并在不同的小块中进行直方图统计(最后把这些小的直方图的描述符线性连接形成总的描述符)。如下图
其实你可以这样想,比如在图片的左上方有个足球,那么普通的spm的直方图比较时会丢失这个足球features的位置信息,因为它是在整幅图片上进行的直方图统计,而改进后的spm则会很好的解决这个问题,例如在左上方方块进行的直方图统计,它比较时会和另一幅的相应位置比较看有没有足球。
参考资料:
K. Grauman and T. Darrell. The Pyramid Match Kernel: Discriminative Classification with Sets of Image Features, ICCV 2005.
Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. S. Lazebnik, C. Schmid, and J. Ponce. CVPR 2006
http://videolectures.net/nips05_grauman_elsf/